Hosting your own local LLM can be fast, secure and private to online alternatives.
Before getting started#
- You’ll need a fairly decent machine if you want quicker responses. But as long as you are using it alone you can get by with a old machine also.
- We’ll use docker to host the LLM and web ui so make sure docker is installed and running.
Installing Ollama#
In this tutorial we’ll use Ollama to host the LLM and later connect an UI. Create a directory called chat and create a compose.yml file inside it.
mkdir chat
cd chat
touch compose.yml
Add the following to the compose.yml file.
services:
ollama:
image: ollama/ollama
container_name: ollama
restart: unless-stopped
ports:
- 11434:11434
volumes:
- ./ollama-data:/root/.ollama
Now, run the container.
docker compose up -d
And go to

Adding the UI for chat#
For the UI we’ll use the open web UI project. To add this we’ll edit the compose.yml file.
services:
ollama:
image: ollama/ollama
container_name: ollama
restart: unless-stopped
ports:
- 11434:11434
volumes:
- ./ollama-data:/root/.ollama
open-webui:
image: ghcr.io/open-webui/open-webui:main
restart: unless-stopped
container_name: ollama-webui
volumes:
- ./open-webui-data:/app/backend/data
environment:
- "OLLAMA_BASE_URL=http://ollama:11434"
ports:
- 3000:8080
Then re-run the containers.
docker compose down
docker compose up -d
Now, navigate to
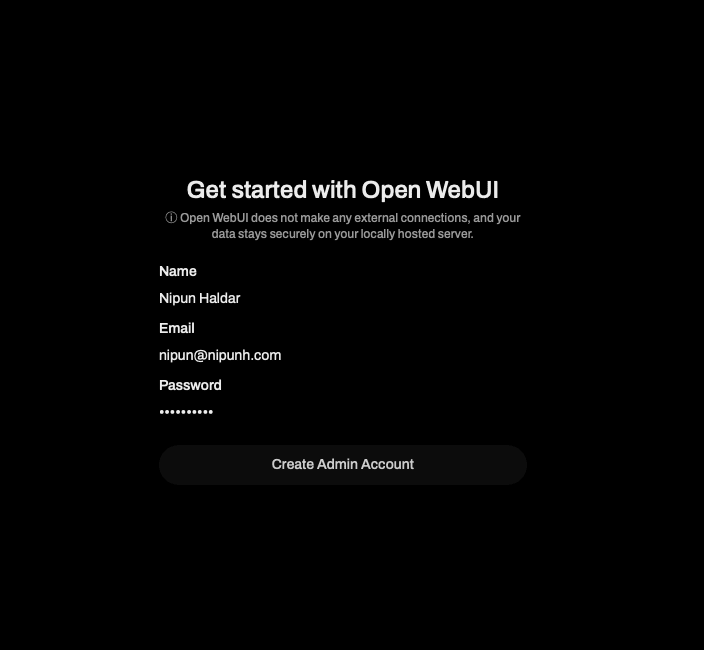
Downloading a LLM#
Now we have all the essentials setup and running to download a use a LLM model. You can any model from the Ollama website. For this tutorial we’ll use the deelseek-r1 model with 1.5 billion parameters.
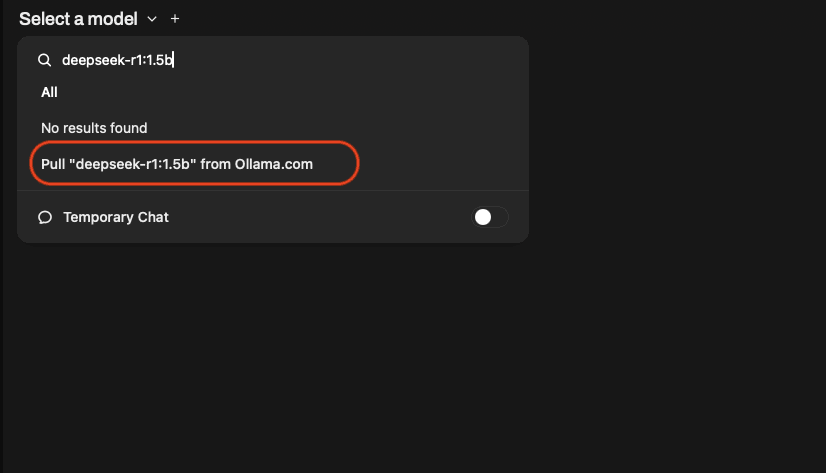
On the web interface go to select model and search deepseek-r1:1.5b and click pull to begin downloading. Wait for the model to get downloaded.
Once the model is downloaded select the model.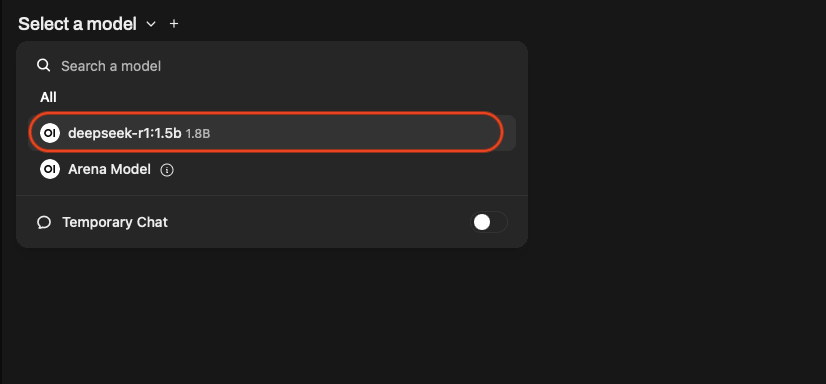
Try to ask it a joke 😂
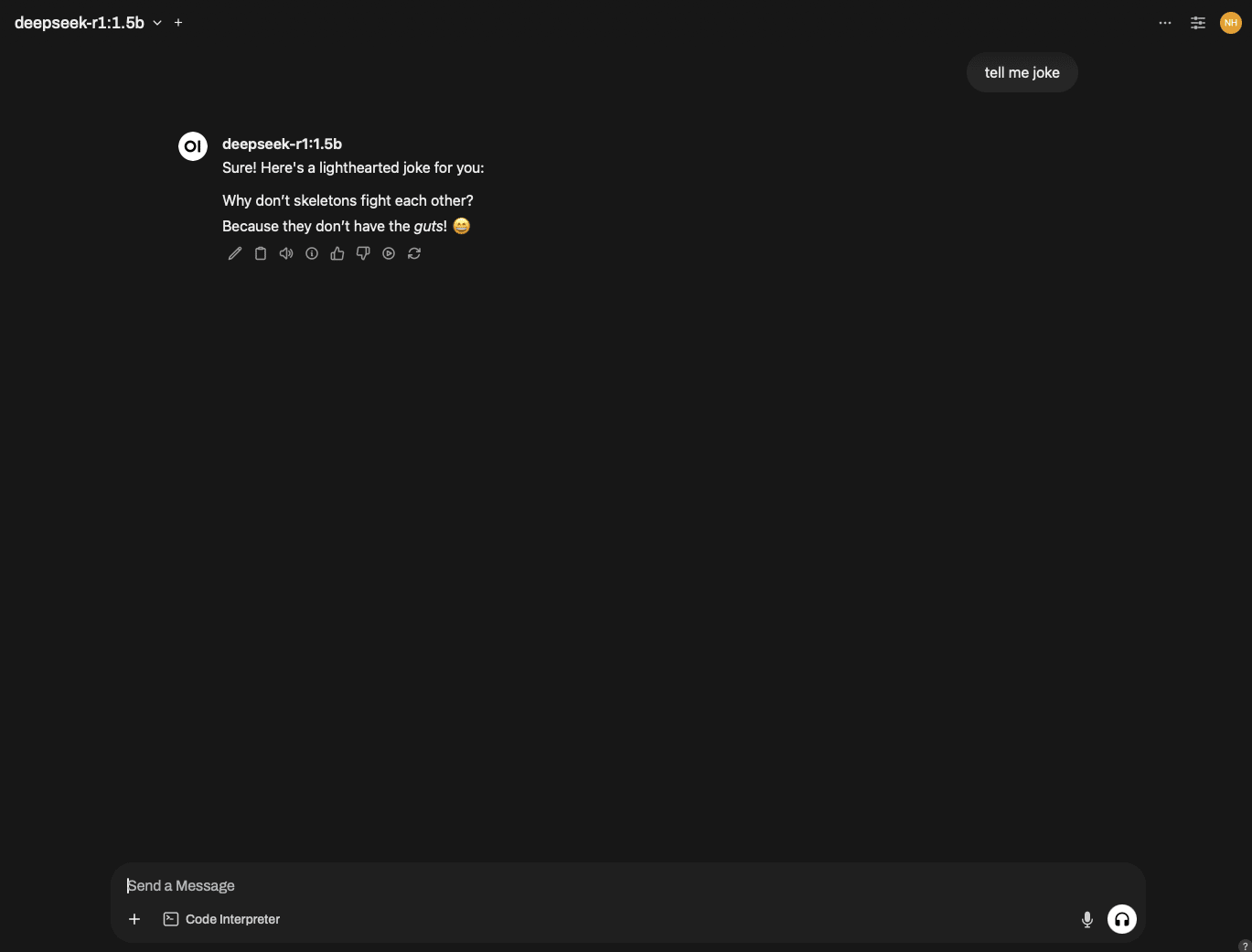
Okay! the jokes might not be as funny 😅 but you have your own private chatbot.